The world of natural language processing (NLP) has been revolutionized by the advent of transformer architecture, a deep learning model that has fundamentally changed how computers understand human language. I find this topic fascinating because it blends complex computational models with real-world applications, effectively allowing machines to interpret and generate text with a level of sophistication previously unattainable. Transformers have become the backbone of many NLP tasks, from text translation to content generation, and continue to push the boundaries of what’s possible in artificial intelligence.
As someone keenly interested in the advancements of AI, I’ve seen how transformer architecture, specifically through models like BERT and GPT, has provided incredible improvements over earlier sequence-to-sequence models. These improvements are not just academic; they have practical implications in a variety of industries, including healthcare, finance, and education. By leveraging the transformer’s ability to understand the context of words in a sentence, NLP applications are now more accurate and efficient, making technology more intuitive and user-friendly.
My exploration of transformer architecture will dive into its key components, such as self-attention mechanisms, which allow the model to weigh the importance of different words in a sentence. I’ll also look at the real-world use cases that showcase the versatility of transformers, from chatbots that can sustain coherent and contextually relevant conversations to sophisticated tools that can summarize extensive documents accurately. The transformer model isn’t just an academic marvel, it’s a testament to human ingenuity and our relentless pursuit to break new ground in the AI landscape.
Core concepts behind Transformers
In this section, I’ll highlight the core principles behind transformers, from their unique abilities to process data in parallel to their application in groundbreaking NLP tasks.
The transformer model represents a significant shift in natural language processing, moving away from sequence-dependent computations which were common in prior models like RNNs and LSTMs.
For more information, read my older blog post here: Evolution of Language Models: From N-Grams to Neural Networks to Transformers
In transformers, the architecture relies on attention mechanisms — specifically self-attention — to weigh the importance of different words within a sentence, irrespective of their position. This model, introduced by Vaswani et al. in the paper “Attention Is All You Need,” has become the foundation for many state-of-the-art NLP techniques.
Self-Attention Mechanism
Self-attention, the core innovation of transformers, enables the model to consider every part of the input sequence simultaneously. The mechanism generates three vectors — queries, keys, and values — for each input token. It then employs a scoring system to decide how much focus (or attention) should be given to other parts of the input sequence when processing a specific part. This allows for a more nuanced understanding of language context and the capturing of dependencies, regardless of sentence length.
Positional Encoding
Since transformers process words in parallel and don’t inherently account for sequence order, positional encoding is added to give each word a unique position. By doing this, the transformer preserves the order of words, maintaining context which is crucial for understanding sentences in natural language. These positional encodings are usually vectors that are added to the input embeddings, retaining the notion of the sequence within the model’s internal representation.
Transformer Architecture
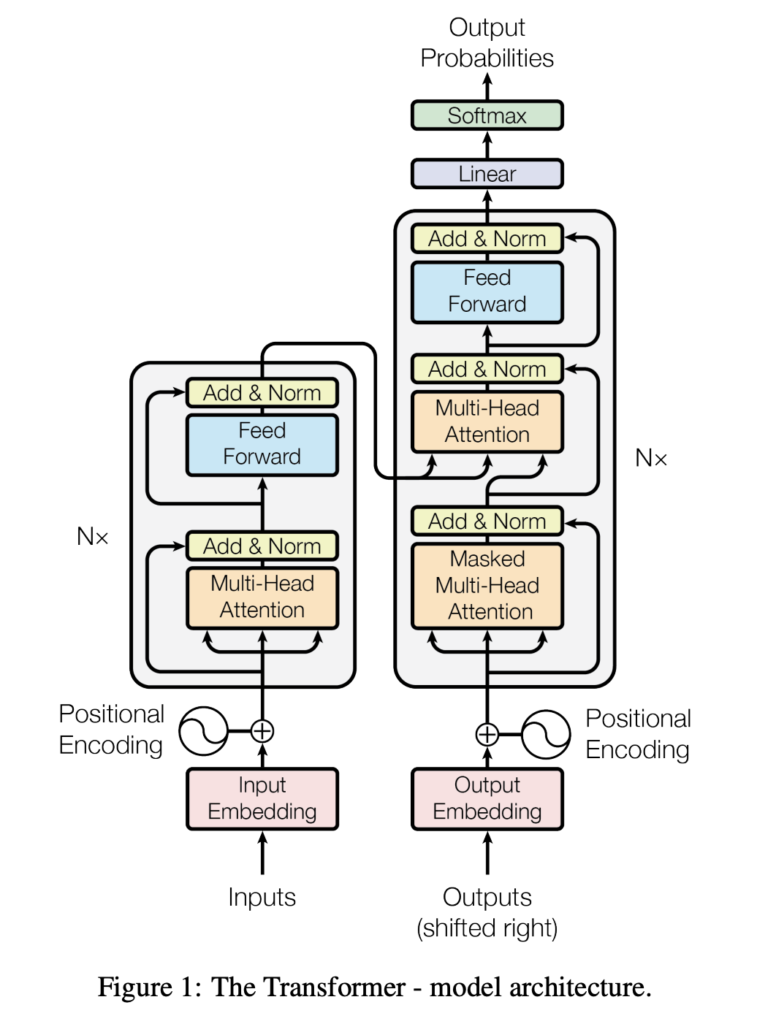
The heart of modern natural language processing lies within the Transformer architecture (proposed in the paper: Attention Is All You Need), which has propelled advances in machine understanding and generation of human language. Let me walk you through its components.
Encoder and Decoder Structure
The Transformer model is built on a foundational structure that includes an encoder to process input data and a decoder that produces the output. Each consists of a stack of identical layers that facilitate the deep learning process.
Multi-Head Attention
Multi-head attention mechanisms are a key feature of the Transformer, allowing it to focus on different positions of the input sequence simultaneously. This lets the model capture a broader context and better understand the relationships between words.
Feed-Forward Neural Networks
Each layer within the encoder and decoder also contains a feed-forward neural network that applies transformations to the data sequentially. This straightforward network structure contributes to the parallelization benefits of Transformers.
Layer Normalization and Residual Connections
The architecture is enhanced by layer normalization and residual connections, which help maintain stability in the training process. These components facilitate smooth information flow across the network and prevent the vanishing gradient problem.
Training Transformers
In training transformers for natural language processing, the choices surrounding loss functions and optimizers are vital. These components can significantly impact the model’s ability to learn from data efficiently and achieve high performance on language tasks.
Loss Functions
For transformers, the loss function is a way to measure how well the model’s predictions match the actual desired outcomes. In language models, I often use Cross-Entropy Loss, which quantifies the difference between the predicted probability distribution and the true distribution. A perfect model would have a cross-entropy loss of zero, indicating complete agreement between predictions and actuals. For example, in a language translation task, if my transformer model predicts the next word in a sentence accurately, the loss is smaller compared to an incorrect prediction.
Optimizer Choices
Choosing the right optimizer is critical for the training process. The optimizer adjusts the weights of the model to minimize the loss function. I’ve found that Adam, a stochastic optimization method, works well for transformers because it adapts the learning rate during training. For larger models, techniques like learning rate warmup and gradient clipping are also beneficial. These methods prevent large updates that could destabilize the learning process, helping to train large-scale transformers more effectively.
Some use cases of LLMs
In my exploration of transformer architecture, I’ve found its applications in large language models (LLMs) to be quite expansive. These models are powerful tools that drive many of today’s AI capabilities.
Natural Language Processing
In Natural Language Processing (NLP), transformers have led to remarkable advancements. I’ll cite an example from a paper where BERT, a renowned transformer-based LLM, is used for tasks like sentiment analysis and question answering (From A survey on large language models). This highlights how effective these models are in understanding and interpreting human language.
Generative Tasks
When it comes to Generative Tasks, the capabilities are truly impressive. I’ve seen transformers used to generate coherent and contextually appropriate text, create dialogue systems, or even generate code. Large language models, such as GPT-3, are great examples here. They can write essays or produce creative content that is often indistinguishable from that written by humans.
Language Translation
Finally, there’s Language Translation, which has been revolutionized by transformers. I’ve read cases where transformer models like those from Huggingface’s initiatives provide state-of-the-art performance, translating between languages with unprecedented accuracy, and maintaining the nuances and idiomatic expressions of each language with finesse. These applications are fundamentally changing how we approach cross-lingual communication.
Sentiment Analysis
When I browse through product reviews or social media comments, it’s insightful to see how sentiment analysis can gauge public opinion. Transformers help businesses analyze large volumes of data to determine customer sentiment, enabling them to respond to market trends faster and tailor their strategies accordingly.
Some Challenges and Considerations
Before delving into the specifics, I’d like to highlight that while transformer architecture has revolutionized NLP, it requires hefty computational power and brings up serious ethical questions. It’s important to navigate these challenges carefully to make the most of the technology.
Not So Green
Transformers are at the heart of many of today’s large language models, but they demand significant computational resources. Training state-of-the-art models often requires clusters of GPUs or TPUs, which can be prohibitively expensive and energy-intensive. Researchers and practitioners like me need to plan for these needs and consider the carbon footprint of such operations.
Ethical Implications
The ethical implications are just as critical. As I share the advances in this field, I must ensure that the models do not perpetuate or amplify biases present in training data. An example that illustrates the gravity of this issue is the use of large language models in healthcare, where biased decision-making could have life-altering consequences. Moreover, there’s an ongoing conversation about the implications of large language models for medical ethics, which anyone in this field ought to follow closely to stay informed.