I am sure you have caught up on the buzz around Large Language Models (LLMs), the backbone of your favorite tool, ChatGPT and so I thought this might be a good time to write a refresher on language models, which includes their definition, evolution, application, and challenges. From n-gram to transformer models like GPT-3 and BERT, language models have come a long way, and now LLMs are leading the way.
Without complicating and using more jargon, I will jump right into language models. Let’s go!
What is a language model?
From Wikipedia: A language model is a probabilistic model of a natural language that can generate probabilities of a series of words, based on text corpora in one or multiple languages it was trained on. If that made your head spin, don’t worry! I am gonna simplify it for you.
A brief history of language models
The history of language models can be traced back to the 1950s when the first statistical language model was introduced. However, it wasn’t until the 2010s that pre-training became a popular approach for language modeling. Pre-training involves training a model on a large corpus of text data before fine-tuning it on a specific task. This approach has been highly successful in improving the performance of language models.
Large language models (LLMs) are a recent development that has taken the field by storm. These models are trained on massive amounts of data and can generate high-quality text that is difficult to distinguish from text written by humans. LLMs have been used for a wide range of applications, including language translation, question-answering, and text summarization.
Mathematical representation
In any language, we have vocabulary and grammar, that help us communicate effectively and clearly. Those rules aren’t clear to computers, as they understand only numbers, so they convert everything into numbers and create meaningful sentences using probability. Let’s look at an example:
I had coffee at coffeeshop — looks good, and makes sense
I had wine at coffeeshop — possible, but the above one makes more sense
Wine had coffee at coffeeshop — what?
Now, machine will assign a probability to each of these series of words after being trained on a plethora of English language-based data. It will assign a higher probability to the first statement, slightly lower for the second, and very low for the third one.
p(I, had, coffee, at, coffeeshop) = 0.015
p(I, had, wine, at, coffeeshop) = 0.02
p(Wine, had, coffee, at, coffeeshop) = 0.00001
Using a language model, we can perform a host of tasks like speech recognition, handwriting recognition, machine translation, informational retrieval, and natural language generation.
How is the probability calculated?
This is done using an auto-regressive model, which forms the backbone of the feed-forward neural network
The probability here is calculated based on the chain rule of probability:
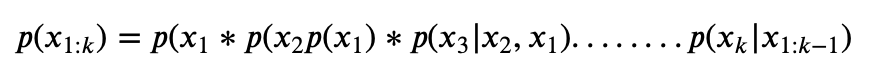
For our example, it will translate to:
p(I, had, coffee, at, coffeeshop) = p(I) * \
p(had|I) * p(coffee| I, had)*
p(at | I, had, coffee) * \
p( coffeeshop | I, had, coffee, at)
Does that look computationally expensive? It is!
While now we have deep learning algorithms that can compute this in the form (with feed-forward neural networks mentioned above), a more computationally efficient method has been used: N-Grams model
N-grams model
In an n-gram model, the prediction of a token $x_{i}$ only depends on the last n−1 characters $x_{i−(n−1):i−1}$ not on the whole corpus of k tokens, as done previously. The probability now would become:
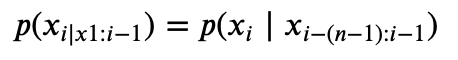
In our example, for a 2-gram model,
p(I, had, coffee, at, coffeeshop) = p(I)
p(I, had, coffee, at, coffeeshop) = p(I) *
p(had|I) * p(coffee| I)*
p(at | had) *
p( coffeeshop | at)
Building an n-gram model is computationally feasible and scalable which has made them a popular model before we had more computational power to fit in neural network models that could fit in more information and enable text generation.
RNNs
RNNs enabled the entire context x_(1:k) to be taken into account, which means implementing the above-mentioned chain rule of probability as is, without simplifying it for n-grams. But they were again quite computationally expensive. RNNs also suffer from the vanishing gradient problem, which limits their ability to learn long-term dependencies. Transformers described above reduced the computational expense without compromising the results by having a fixed context length of “n” tokens, but the good thing is that you can make n large enough.
Transformer model
Recently, transformer models have emerged as the state-of-the-art in language modeling. Transformers use self-attention mechanisms to attend to all words in a sentence simultaneously, allowing them to capture global dependencies and relationships. They also use positional encoding to preserve the order of words in a sentence. Transformer models, such as BERT and GPT-2, have achieved impressive results in a variety of natural language tasks, including question answering, sentiment analysis, and text generation.
In summary, the foundations of language models have evolved from simple n-gram models to more sophisticated neural networks and transformer models. These models have increased our understanding of language and improved the performance of natural language processing applications.
The biggest breakthroughs came with GPT-3 and GPT-4
One of the most significant breakthroughs in LLMs was the introduction of the GPT-3 model by OpenAI in 2020. GPT-3 is a 175 billion parameter model that has set new standards in natural language processing. It has demonstrated remarkable capabilities, such as generating coherent and contextually relevant text, completing tasks with high accuracy, and even creating original content.
The success of GPT-3 has spurred further research in the field, with OpenAI releasing the GPT-4 model which is a multi-modal model, which means it can deal with texts and images.
Applications and Impact of Language Models
As language models have evolved, their applications and impact have grown significantly. In this section, I will discuss some of the most important applications of language models and their impact on various fields.
Natural Language Processing Tasks
Language models are used in a wide range of NLP tasks, including sentiment analysis, language translation, and speech recognition. With the help of language models, NLP algorithms can now understand the context and meaning of words, making them much more accurate and efficient.
Generative AI and Code Generation
Language models have also been used in generative AI, where they are used to create realistic text, audio, and video content. They have been particularly successful in generating human-like text (well, close to humans — not exactly like humans), which has been used in chatbots, virtual assistants, and other conversational interfaces. In addition, language models have been used to generate code, making it easier for developers to write complex software programs. I will be honest, this ability scares me about my job sometimes!
Question Answering and Reasoning
Language models have also been used in question-answering and reasoning systems, where they are used to answer complex questions and solve problems. They have been particularly successful in domains such as healthcare, finance, and law, where they are used to analyze large amounts of data and provide insights and recommendations.
Are LLMs perfect?
Short answer: they are far from being perfect as they come with their own challenges. In this section, I will discuss some of the key challenges and future directions for language models.
Bias and Fairness
One of the most pressing challenges facing language models is the issue of bias. Language models are often trained on large datasets that contain biases and stereotypes, which can lead to biased or unfair results. To address this challenge, we need to develop new techniques for detecting and mitigating bias in language models. This includes developing more diverse datasets and incorporating fairness metrics into the training process.
Disinformation and Quality Control
Another challenge is the issue of disinformation and quality control. Language models can be used to generate fake news or misleading information, which can have serious consequences. To address this challenge, we need to develop new techniques for detecting and filtering out disinformation in language models. This includes developing more sophisticated quality control algorithms and incorporating human oversight into the training process.
Efficiency and Capacity
Finally, there is the challenge of efficiency and capacity. Language models are becoming increasingly complex and resource-intensive, which can make them difficult to train and deploy. To address this challenge, we need to develop new techniques for optimizing the efficiency and capacity of language models. This includes developing more efficient algorithms and hardware architectures, as well as exploring new approaches to distributed training.
I will write more on LLMs, covering important concepts and building applications with foundation models, stay tuned.