Shruti Pandey
Seasoned Data Scientist with a Flair for Machine Learning Innovation and Strategic Business Impact
Data Scientist @ Nationwide
Hi! I am Shruti Pandey
My 5 years of professional experience in data has enabled me to design impactful business solutions at Nationwide Insurance, consult Fortune 500 companies, and improve community outcomes in tribal districts in India.
In my current role at Nationwide, I am leveraging data analysis and predictive modeling to optimize business performance and drive financial success, while working closely with business partners. I am also supporting various initiatives that are exploring business use cases for Large Language Models (LLMs) and designing evaluation guidelines for Generative AI (Gen AI) foundation models.
In my next opportunity, I want to contribute my proficiency in quantitative analytics, predictive modeling, and Natural Language Processing (NLP) to drive business success. With a proven track record and a passion for applied mathematics and statistical modeling, I am ready to transform challenges into data-driven opportunities for growth.

Skills and Expertise
Python
5+ years of work experience in coding in Python and using mathematical, data manipulation, and visualisation libraries like Numpy, Pandas, Matplotlib, Seaborn, Scipy, etc.
R
5+ years of work experience in coding in R and using mathematical, data manipulation, and visualisation libraries like Dplyr, Tidyr, Ggplot, Shiny for interactive dashboards, etc.
Databases
5+ years of work experience in database management, performance tuning and query optimization with SQL and NoSQL databases, database administration for MySQL and PostgreSQL, MongoDB, etc.

Visualization
5+ years of work experience in visualization tools for business analytics like Power BI, Tableau, Dash, Streamlit in Python for interactive dashboards, complemented by dynamic web visualizations crafted with D3.js

Machine Learning
5+ years of work experience in utilizing Python’s scikit-learn for regression, classification, and clustering tasks, ensemble methods, support vector machines, and decision trees, as well as experience with R for statistical analysis and predictive modeling

Deep Learning
3+ years of experience in using PyTorch for building Recurrent Neural Networks (RNNs) for advanced Natural Language Processing (NLP) applications and TensorFlow for crafting sophisticated models like Convolutional Neural Networks (CNNs) for computer vision tasks

Generative AI (LLMs)
1 year of experience with large language models OpenAI’s GPT-3, BERT, Lllama in NLP tasks. Currently reviewing evaluation frameworks like RAGAS, HELM, Llama Index, etc., governance guidelines and Model Cards at Nationwide for ethical and resposnible use of Generative AI models
Advanced Mathematics
Took Graduate level courses at Duke University in Multivariate Calculus, Linear Algebra and Matrix Analysis, Probability Theory and Stochastic Processes, Statistical Inference and Hypothesis Testing, Optimization Techniques, Game Theory and Decision Models

Business Acumen
Demonstrated ability to comprehend and align with organizational objectives, utilizing data analytics to inform strategic decision-making and drive impactful business outcomes that resonate with stakeholders’ visions and market demands.
Collaboration & teamwork
Proven track record of successful partnerships with cross-functional teams and stakeholders, where I’ve consistently facilitated data-driven solutions and fostered synergistic environments to achieve collective goals

Responsbile AI
Committed to responsible AI practices, focusing on the development of systems that prioritize user needs, fairness, and transparency, thereby ensuring that AI technologies serve to enhance human decision-making and well-being.
Selective Projects
Hand-picked projects to showcase my skills and expertise in Data Analysis, Data Visualization, Machine Learning, Deep Learning, and Natural Language Processing
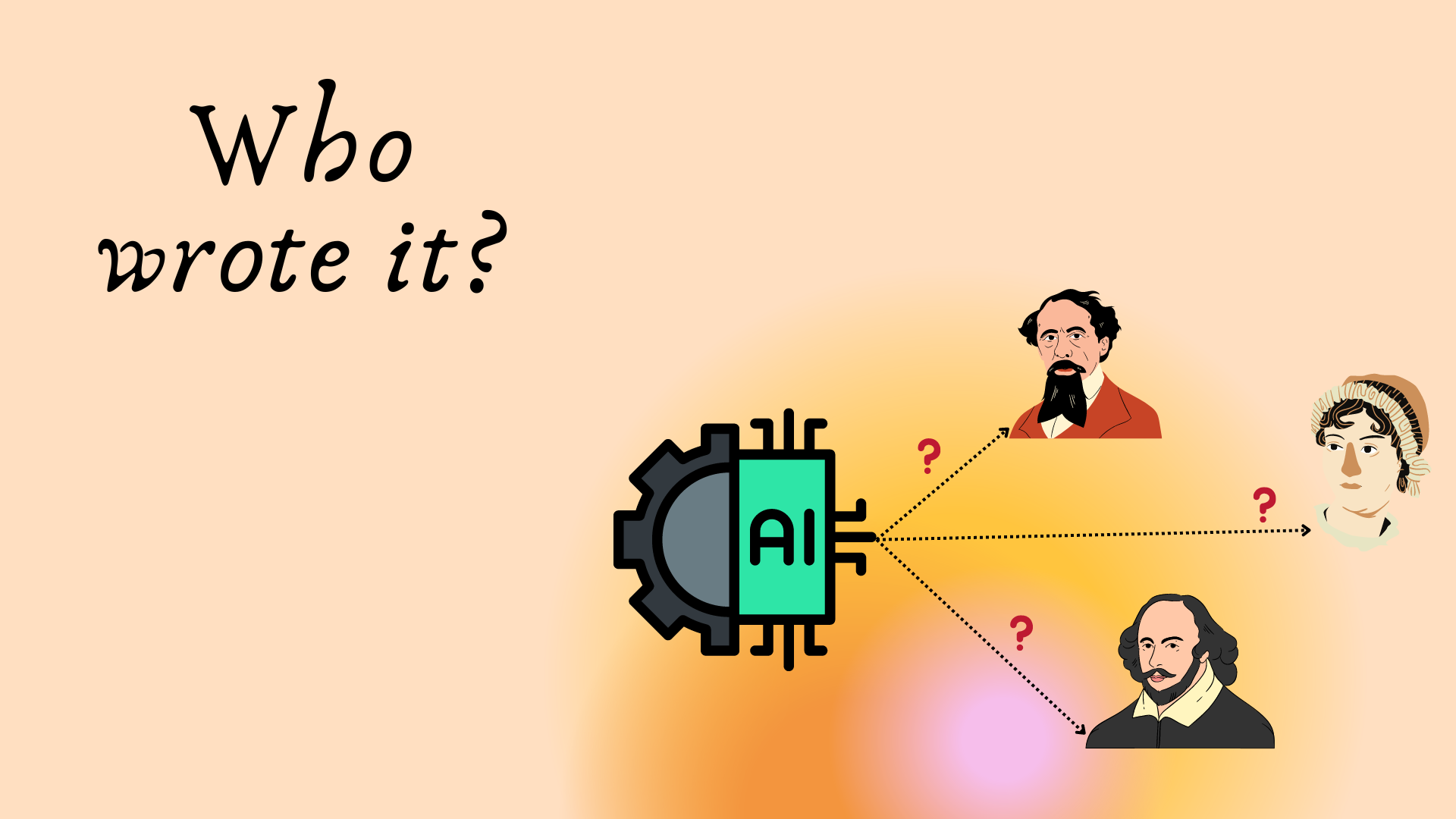
Authorship Identification Using Bidirectional LSTM [Github]
- This was my final project to defend my graduate degree at Duke University and a part of ECE 684: Natural Language Processing. I created a custom dataset for the project using the Gutenberg project by scraping text from 18 books written by 12 authors, with a maximum of 3 books per author. Another dataset I used to train and test my model was the Reuters 50-50 dataset from the UCI Machine Learning Repository. After comparing and contrasting the performance of the generative probabilistic model and discriminative neural network model on Reuters 50 50 and Gutenberg datasets, I observed that Article level LSTM performs the best on authorship identification with an accuracy of 68.8% and 79.28% on Reuters 50 50 and Gutenberg dataset respectively.

S&P Forecasting with DeepAR algorithm [Github]
- SP500 Dataset being market data has been quite volatile over the years. In this project, I made use of the DeepAR model, coding from scratch using the algorithm described in the paper. When DeepAR was used to predict stocks value, the RMSE remains unstable and fluctuates between 40-200. The model performs well for companies whose stocks tend to move together like Apple, Facebook, Amazon, etc. For a random set of companies, the model gives very high RMSE values, to the magnitude of 1000.
- After normalizing the data and removing the trend, the model improves a lot and the RMSE drops to 0.269 (mean).

Upcoming
I am speaking at the Institute for AI transformation’s
Leaders in AI summit in Austin, Texas
Latest Blog Posts
-
In-Context Learning for LLMs: Zero, One, and Few Shot Learning Examples
In-context learning is a powerful tool that has revolutionized the field of natural language processing (NLP). It allows language models to learn from context and adapt their behavior accordingly. In this blog post, I will discuss the relevance of in-context learning to large language models (LLMs) and explore the concept of in-context learning with zero-shot,…
-
Transformer Architecture: Explained
The world of natural language processing (NLP) has been revolutionized by the advent of transformer architecture, a deep learning model that has fundamentally changed how computers understand human language. I find this topic fascinating because it blends complex computational models with real-world applications, effectively allowing machines to interpret and generate text with a level of…
-
Everything you wanna know about prompting and prompt engineering
The intersection of language and technology has always fascinated me, especially with the rise of Large Language Models (LLMs), which have fundamentally changed how we interact with machines. When I started machine learning, it was mostly people working in data that routinely interacted with AI, but now everyone has access to AI systems on their…
-
Evolution of Language Models: From N-Grams to Neural Networks to Transformers
I am sure you have caught up on the buzz around Large Language Models (LLMs), the backbone of your favorite tool, ChatGPT and so I thought this might be a good time to write a refresher on language models, which includes their definition, evolution, application, and challenges. From n-gram to transformer models like GPT-3 and…
-
How is AI compromising Consumer Privacy?
I was out for dinner with my friends and I was humming “Take Five” with my jazz-fanatic friend. Another friend asked us the name of the song and I said it’s Take Five. The next day, the same friend received an ad from Take Five, the oil-changing company. This was terrifying. My fears about devices…
-
Can we disassociate race from AI?
This semester (Spring 2023), I got an opportunity to assist Dr. Charmaine Royal with her course Race, Genomics, and Society. We had our last class in the past week and Dr. Royal asked us to take the learnings from the class to real-world. In other words, moving from bench side to curbside when it comes…
Get In Touch
If you are curious about my work, or just wanna say hi, get in touch using my contact information